
Les expressions régulières (ou regex) sont principalement connues des développeurs, mais elles peuvent aussi grandement vous aider pour vos travaux textuels. Une expression régulière n’est ni plus ni moins un motif textuel, autrement dit une séquence textuelle générique. Elles sont beaucoup utilisées par les développeurs car elles permettent de valider la forme d’un texte saisi par l’utilisateur, par exemple vérifier que ce dernier entre bien un numéro de téléphone dans un champ de formulaire.
Lorsqu’on manipule de grandes quantités de texte, réparties sur un ou plusieurs fichiers, et qu’on souhaite appliquer des corrections globales, les regex sont vraiment d’un grand secours. Elles permettent de rechercher des occurrences similaires mais non identiques et de les corriger au besoin.
Par exemple, l’expression [mM]ots?[\s-]+cl(ef|é)s? va me permettre de retrouver toutes les occurrences du terme "mot clé" quelle que soit sa graphie et son nombre (mot clé, mot-clé, mots clé, mot clés, mots clef, mots-clef, etc.). Je peux ensuite facilement harmoniser son écriture.
Vous pouvez les utiliser avec de nombreux logiciels (traitement de texte, simple éditeur, InDesign, etc.).
Chez D-BookeR, on les utilise principalement de trois manières :
- avec perl : pour appliquer des corrections automatiques ;
- avec grep : pour faire des recherches au sein des textes sans avoir à ouvrir tous les fichiers ;
- avec kate : pour tester les expressions, les ajuster et appliquer des corrections globales semi-manuellement sur un ensemble de fichiers non ouverts.
Les possibilités sont nombreuses, et vous l’aurez compris, toute la difficulté est de décrire le motif de sorte à ne pas obtenir de faux positifs ni d’oublier certaines occurrences. Sans parler que le codage des expressions peut légèrement différer selon l’environnement où on les utilise.
C’est cette complexité qui fait généralement peur dès lors qu’on parle des expressions régulières. Mais l’outil est tellement pratique qu’il est dommage de s’en passer. Allez-y donc très progressivement dans son utilisation et testez vos expressions avant d’appliquer automatiquement des modifications. Par exemple, si vous les utilisez sous LibreOffice, activez le suivi de correction pour pouvoir ensuite les vérifier. Petit à petit vous gagnerez en assurance et mémoriserez les codage les plus utiles.
CONSTRUIRE UNE EXPRESSION RÉGULIÈRE
Pour construire vos expressions, aidez-vous d’internet, mais aussi de la documentation des logiciels que vous utilisez. Celle-ci comprend presque toujours un chapitre sur les expressions régulières avec la liste et signification des symboles supportés.
Voici quelques codages pratiques :
[Mm] → indique qu’une des lettres contenues entre les crochets doit être présente
M|m → indique la présence de la lettre M ou m
\d → indique la présence d’un chiffre
\w → indique la présence d’un caractère alphanumérique (lettre majuscule ou minuscule, accentuée ou non, chiffre de 0 à 9 et le caractère de soulignement_ )
\s → indique la présence d’un espace quelconque
\n → indique la présence d’un retour à la ligne (signification parfois différente selon les logiciels)
? → indique zéro ou une occurrence de l’élément qui le précède. Exemple : s? indique avec ou sans s
* → indique zéro ou plusieurs occurrences de l’élément qui le précède
+ → indique une ou plusieurs occurrences de l’élément qui le précède
(?<=) lookbehind positif, (?=) lookahead positif → indique que le motif doit être précédé ou suivi par un élément donné. Exemple : auto(?=i|u) : autoimmune (→ auto-immune) mais pas autoévaluation
(?<!) lookbehind négatif, (?!) lookahead négatif → indique que le motif ne doit pas être précédé ou suivi par un élément donné
(l[ea]) → pour capturer le motif décrit entre parenthèses et le restituer dans le remplacement. Exemple ici, sera restitué "le" ou "la" selon l’occurrence. Le code de restitution se présente selon les logiciels sous la forme de \1, \2,… \n ou $1, $2,... $n (1er élément, 2ième, … nième)
LES REGEX PEUVENT FACILITER TOUT UN TAS DE MANIPULATIONS
Dès lors que vous manipulez beaucoup de documents écrits, vous pouvez vous éviter un grand nombre de d’opérations laborieuses à l’aide des regex. Et pas seulement de la correction.
Deux exemples :
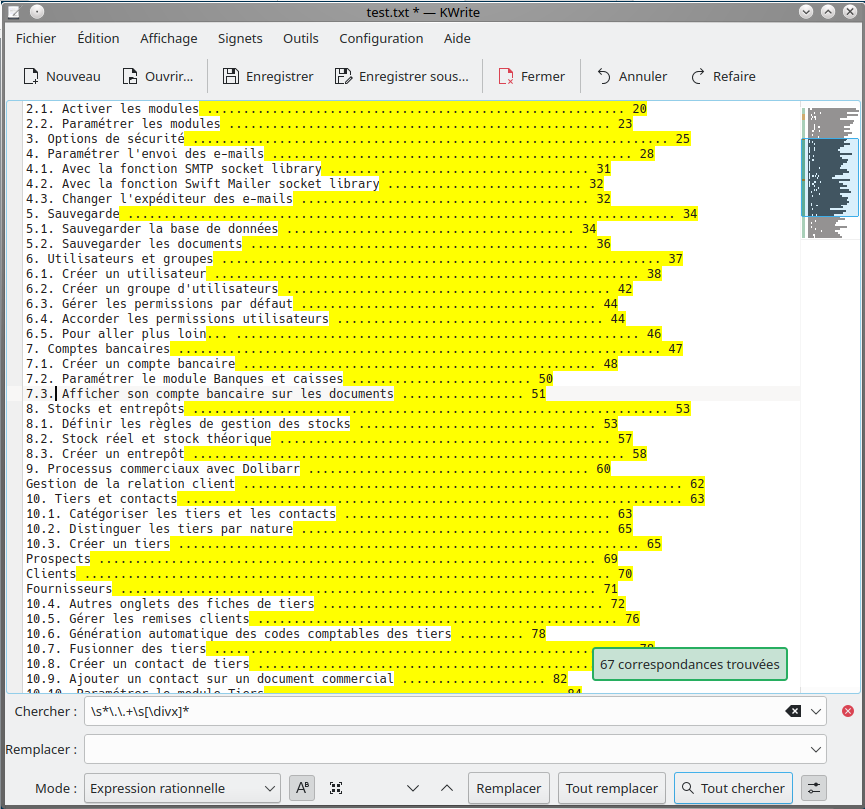
Nettoyage d’une table des matières
Copier-coller d'un PDF, avec des points et numéros de page inutiles. Une expression suffit pour tout remettre au propre :
\s*\.\.+\s[\divx]*
Ajout de l’attribut langue dans un contenu epub
Le validateur d'epub ACE vous indique qu'il manque un attribut langue dans certaines de vos balises <html> et votre epub contient une trentaine de fichiers. Vous pouvez corriger cela à la volée sans ouvrir les fichiers à l'aide de Kate et d'une expression régulière élémentaire :
<html\s*(?!xml:lang)
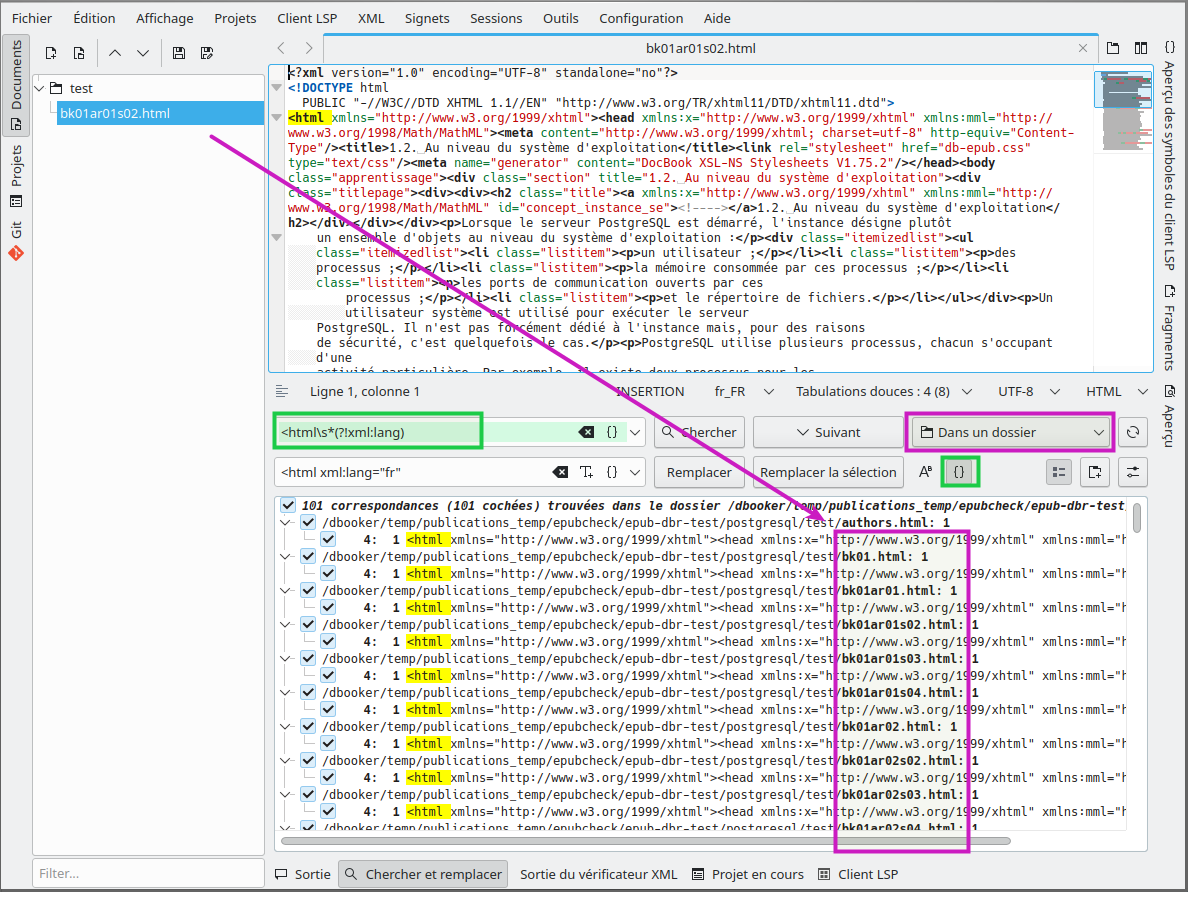
On notera, ici, la sélection d'une recherche sur l'ensemble des fichiers d'un dossier (seul le fichier bk01pr01s02.html a été ouvert, pour lancer l'application - encadrés violets). Nous précisons au logiciel que la séquence de recherche contient une expression régulière (encadrés verts).
QUELQUES RÉFÉRENCES
➤ Page sur les expressions régulières de la documentation LibreOffice
➤ Livre de Laurent Tournier : GREP et InDesign – Rechercher, remplacer et formater en un clic
➤ Testeur d'expressions régulières regex101